发布:2021/4/2 11:24:38作者:管理员 来源:本站 浏览次数:1038
本文简要分析一下如何如何使用C#简单实现合并和拆分word文档。平时我们在处理多个word文档时,可能会想要将两个文档合并为一个,或者是将某个文档的一部分添加到另一个文档中,有的时候也会想要将文档拆分。在Word中,合并或拆分文档最简单的方式就是打开一个原文档的副本文件,复制我们需要的部分,删除不需要的部分,然后再保存文档。使用这种方法在文档比较多或者比较大时手动操作起来比较费时,以下是使用C#实现合并一个Word文档的某一个section到另一个文档或者合并两个完整的Word文档到一个单独的文档以及如何根据section和page break来拆分一个Word文档的方法。
第一部分:合并Word文档
为了数据的保密性,我新创建了两个简单的word文档,如下图:
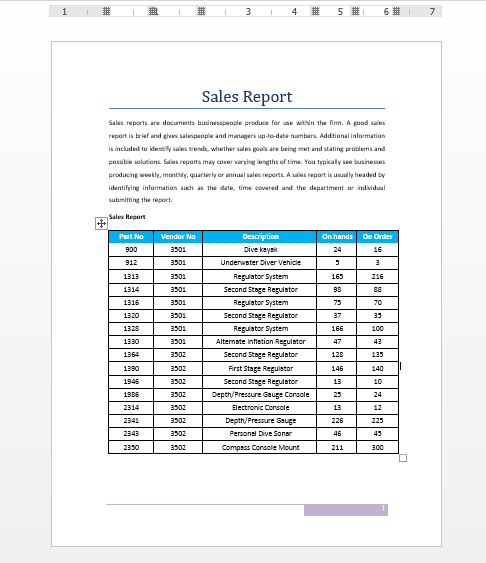
文档1
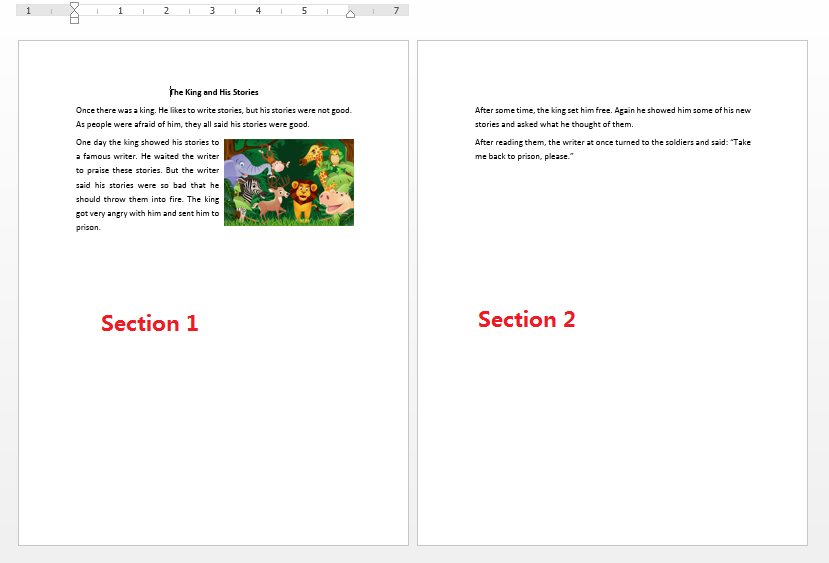
文档2
合并一个Word文档的某一个section到另一个文档
//加载文档1和文档2 Document doc1 = new Document();
doc1.LoadFromFile("Sales Report.docx", FileFormat.Docx);
Document doc2 = new Document();
doc2.LoadFromFile("Stories.docx", FileFormat.Docx); //获取文档2的第一个section Section sec = doc2.Sections[0]; //克隆该section并把它添加到文档1 doc1.Sections.Add(sec.Clone());
doc1.SaveToFile("Mergesection.docx", FileFormat.Docx);
效果图:

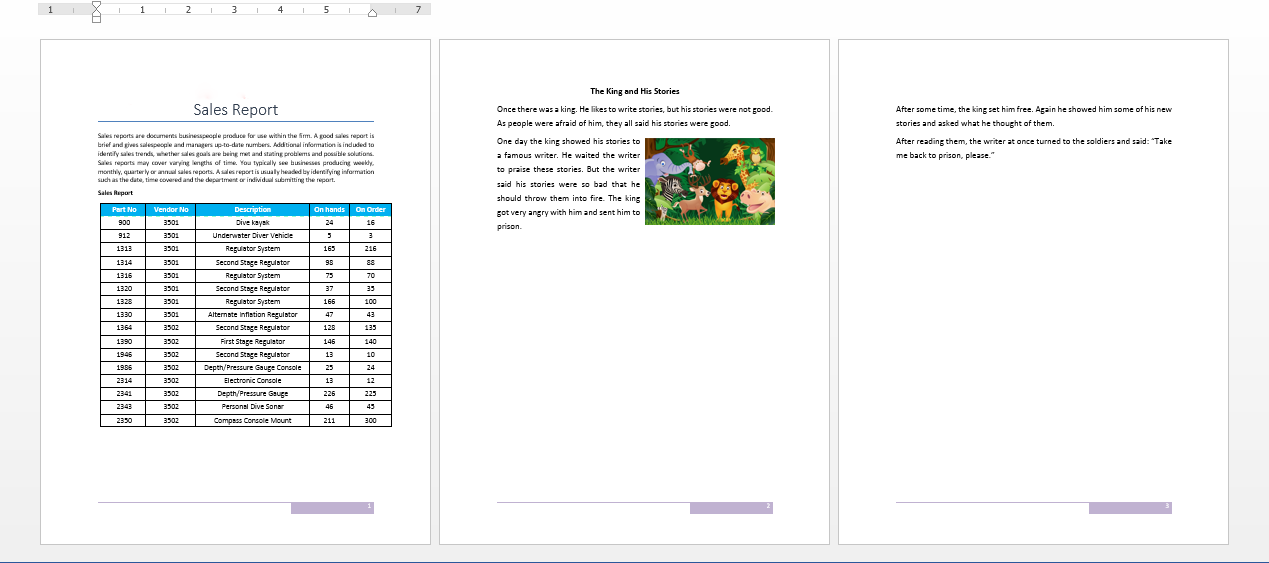
合并两个完整的Word文档到一个单独的文档
//加载文档1 Document document = new Document();
document.LoadFromFile("Sales Report.docx", FileFormat.Docx); //将文档2的所有内容插入到文档1 document.InsertTextFromFile("Stories.docx", FileFormat.Docx); //将结果另存为到另一个单独的文档 document.SaveToFile("MergeFiles.docx", FileFormat.Docx);
效果图:
第二部分:拆分Word文档
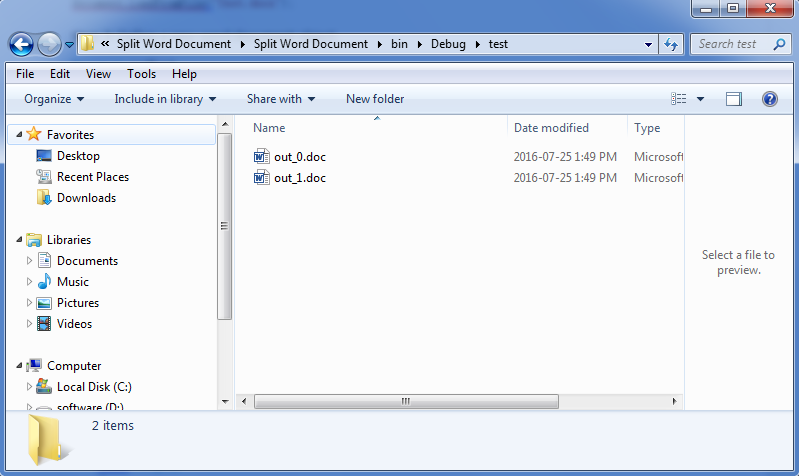
根据section break拆分Word文档
//加载源文档 Document document = new Document();
document.LoadFromFile("Stories.docx"); //定义一个新的文档对象 Document newWord; //遍历源文档的所有section,克隆每个section并将其添加至一个新的word文档,然后保存文档 for (int i = 0; i < document.Sections.Count; i++)
{
newWord = new Document();
newWord.Sections.Add(document.Sections[i].Clone());
newWord.SaveToFile(String.Format(@"test\output_{0}.docx", i));
}
效果图:
根据page break拆分Word文档
如下文档含有两个page break分别在第一页和第二页的末尾:

//加载源文档 Document original = new Document();
original.LoadFromFile("New Zealand.docx"); //创建一个新的文档并给它添加一个section Document newWord = new Document();
Section section = newWord.AddSection(); int index = 0; //遍历源文档的所有section,检测page break并根据page break拆分文档 foreach (Section sec in original.Sections)
{ foreach (DocumentObject obj in sec.Body.ChildObjects)
{ if (obj is Paragraph)
{
Paragraph para = obj as Paragraph;
section.Body.ChildObjects.Add(para.Clone()); foreach (DocumentObject parobj in para.ChildObjects)
{ if (parobj is Break && (parobj as Break).BreakType == BreakType.PageBreak)
{ int i = para.ChildObjects.IndexOf(parobj); for (int j = i; j < para.ChildObjects.Count; j++)
{
section.Body.LastParagraph.ChildObjects.RemoveAt(i);
}
newWord.SaveToFile(String.Format("result/out-{0}.docx", index), FileFormat.Docx);
index++;
newWord = new Document();
section = newWord.AddSection();
section.Body.ChildObjects.Add(para.Clone()); while (i >= 0)
{
section.Paragraphs[0].ChildObjects.RemoveAt(i);
i--;
} if (section.Paragraphs[0].ChildObjects.Count == 0)
{
section.Body.ChildObjects.RemoveAt(0);
}
}
}
} if (obj is Table)
{
section.Body.ChildObjects.Add(obj.Clone());
}
}
}
newWord.SaveToFile(String.Format("result/out-{0}.docx", index), FileFormat.Docx);
效果图:
完整代码:
合并
using Spire.Doc; namespace Merge_Word_Document
{ class Program
{ static void Main(string[] args)
{ //合并一个Word文档的某一个section到另一个文档 /*Document doc1 = new Document();
doc1.LoadFromFile("Sales Report.docx", FileFormat.Docx);
Document doc2 = new Document();
doc2.LoadFromFile("Stories.docx", FileFormat.Docx);
Section sec = doc2.Sections[0];
doc1.Sections.Add(sec.Clone());
doc1.SaveToFile("Mergesection.docx", FileFormat.Docx);*/ //合并两个完整的Word文档到一个单独的文档 Document document = new Document();
document.LoadFromFile("Sales Report.docx", FileFormat.Docx);
document.InsertTextFromFile("Stories.docx", FileFormat.Docx);
document.SaveToFile("MergeFiles.docx", FileFormat.Docx);
}
}
}
拆分
using System; using Spire.Doc; using Spire.Doc.Documents; namespace Split_Word_Document
{ class Program
{ static void Main(string[] args)
{ //根据section拆分 /*Document document = new Document();
document.LoadFromFile("Stories.doc");
Document newWord;
for (int i = 0; i < document.Sections.Count; i++)
{
newWord = new Document();
newWord.Sections.Add(document.Sections[i].Clone());
newWord.SaveToFile(String.Format(@"test\out_{0}.docx", i));
}*/ //根据page break拆分 Document original = new Document();
original.LoadFromFile("New Zealand.docx");
Document newWord = new Document();
Section section = newWord.AddSection(); int index = 0; foreach (Section sec in original.Sections)
{ foreach (DocumentObject obj in sec.Body.ChildObjects)
{ if (obj is Paragraph)
{
Paragraph para = obj as Paragraph;
section.Body.ChildObjects.Add(para.Clone()); foreach (DocumentObject parobj in para.ChildObjects)
{ if (parobj is Break && (parobj as Break).BreakType == BreakType.PageBreak)
{ int i = para.ChildObjects.IndexOf(parobj); for (int j = i; j < para.ChildObjects.Count; j++)
{
section.Body.LastParagraph.ChildObjects.RemoveAt(i);
}
newWord.SaveToFile(String.Format("result/out-{0}.docx", index), FileFormat.Docx);
index++;
newWord = new Document();
section = newWord.AddSection();
section.Body.ChildObjects.Add(para.Clone()); while (i >= 0)
{
section.Paragraphs[0].ChildObjects.RemoveAt(i);
i--;
} if (section.Paragraphs[0].ChildObjects.Count == 0)
{
section.Body.ChildObjects.RemoveAt(0);
}
}
}
} if (obj is Table)
{
section.Body.ChildObjects.Add(obj.Clone());
}
}
}
newWord.SaveToFile(String.Format("result/out-{0}.docx", index), FileFormat.Docx);
}
}
}
注意:这里我使用了一个免费的word API(http://freeword.codeplex.com)。